
深度學習應用到語音識別領域后,詞錯率有了顯著降低。但是語音識別尚未達到人類水平,然后存在多個亟待解決的問題。本文從口音、噪聲、多說話人、語境、部署等多方面介紹了語音識別尚未解決的問題。
深度學習被應用在語音識別領域之后,詞錯率有了顯著地降低。然而,盡管你已經讀到了很多這類的論文,但是我們仍然沒有實現人類水平的語音識別。語音識別器有很多失效的模式。認識到這些問題并且采取措施去解決它們則是語音識別能夠取得進步的關鍵。這是把自動語音識別(ASR)從「在大部分時間對部分人服務」變成「在所有時間對每個人服務」的唯一途徑。
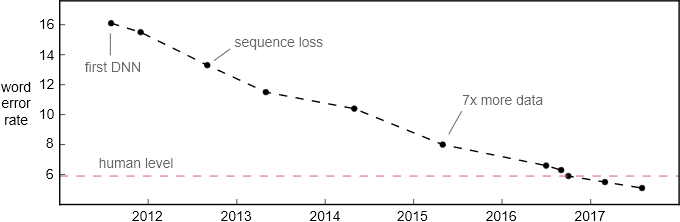
詞錯率在 Switchboard 對話語音識別基準上的提升。該測試集于 2000 年收集,包括 40 個電話錄音,每段對話都發生在隨機抽取的兩個英語母語者之間。
如果說基于 Switchboard 的對話語音識別結果達到了人類水平,這無異于說自動駕駛在陽光明媚、交通順暢的小鎮上達到了人類的駕駛水平。盡管語音識別在對話語音上的進步很明顯。但是認為其達到人類水平的說法終究太寬泛了。以下是語音識別領域仍待提升的一些方面。
口音和噪聲
語音識別最明顯的一個缺陷在于對口音和背景噪聲的處理。最直接的原因就是:絕大多數訓練數據都由具有高信噪比的美式英語組成。例如,Switchboard 對話語音訓練和測試集都是英語母語者(大部分是美國人)在幾乎無噪聲的環境中錄制的。
但是,更多訓練數據本身也沒有克服這個問題。很多語言都是有方言和口音的。對每一種情況都收集足夠多的標注數據是不可行的。開發一款僅僅針對美式英語的語音識別器就需要 5 千多個小時的轉錄音頻數據!
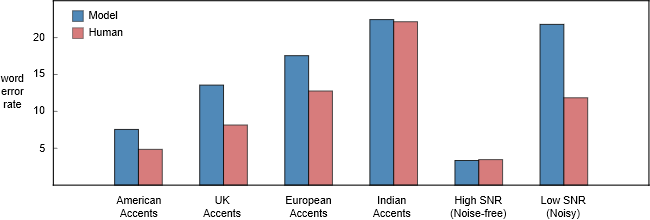
不同類型的語音數據上,百度 Deep Speech 2 模型和人類聽寫員的詞錯率對比。我們注意到在非美國口音的語音上,人類聽寫員表現得要差勁一些。這可能是因為聽寫員大多數是美國人。我希望在某個區域的本地聽寫員要有更低的錯誤率。
至于背景噪聲,一輛行駛的汽車內的噪聲幾乎不可能有-5dB 那么低。人類在這種環境中能夠輕易理解彼此所說的話,然而語音識別器的性能則會因為噪聲的存在而急劇下降。從上圖中我們可以發現,人類和模型的詞錯率差距在低信噪比和高信噪比音頻之間存在巨大的差距。
語義錯誤
通常,詞錯率并不是一個語音識別系統的實際目標。我們所關心的是語義錯誤率,即未正確理解含義的話語片段所占的比例。
舉一個例子:如果某人說「let's meet up Tuesday」(周二見),而語音識別器理解成了「let's meet up today」(今天見)。在沒有語義錯誤的情況下也會出現詞錯率。在這個例子中,如果語音識別器丟掉了「up」,將語音識別成了「let's meet Tuesday」,則這個句子的語義并沒有發生改變。
在使用詞錯率作為標準的時候我們必須謹慎一些。5% 的詞錯率大約對應每 20 個單詞會有一個出錯。如果一個句子共有 20 個單詞(英文句子平均就是這個長度),那么在這種情況下句錯率就是 100%。我們希望出錯的單詞不會改變句子的意思,否則即使詞錯率只有 5%,語音識別器也有可能把整句的意思都弄錯。
將模型與人類相比較的時候,很重要的一點是要去檢查錯誤的本質,而不是僅僅關注詞錯率(WER)這個結論性的數字。從我的經驗來看,人類轉錄的時候一般會比識別器較少出錯,尤其是嚴重的語義錯誤。
微軟的研究者最近對比了人類和微軟人類級別語音識別器所犯的錯誤 [3]。他們發現二者的一個差異是:模型比人類更頻繁地混淆「uh」(嗯)和「uh huh」(嗯哼)。這兩個詞組的語義有很大不同:「uh」只是一個語氣填充詞,而「uh huh」表示附和和認同。人類和模型都犯了不少類似的錯誤。
單聲道、多個說話人
Switchboard 對話語音識別任務比較容易,因為每個說話人都使用獨立的麥克風進行錄音。在同一段音頻流中不存在多個說話人的語音重疊。然而,人類即使在多個說話人同時說話的時候也能夠理解說話內容。
一個好的對話語音識別器必須能夠根據正在說話的人(音源)來分割音頻。它還應該理解多個說話人語音重疊的音頻(聲源分離)。這應該在無需給每個說話人嘴邊安裝一個麥克風的情況下實現,這樣對話語音識別就能夠在任意位置奏效。
域變化
口音和背景噪聲只是語音識別器增強魯棒性以解決的兩個問題。這里還有其他一些因素:
變化的聲學環境中的回音
硬件的缺陷
音頻編解碼和壓縮的缺陷
采樣率
說話人的年齡
大多數人甚至分不清 mp3 文件和 wav 文件的差異。在我們宣稱語音識別器的性能達到人類水平之前,它需要對這些問題足夠魯棒。
語境
你會注意到人類水平的錯誤率在類似于 Switchboard 的基準測試集上實際是很高的。如果在和朋友交談的時候,他在每 20 個詞中誤解一個詞,那么你是很難與他交流下去的。
其中的原因是,這個測評是在不考慮語境的情況下進行的。在現實生活中,有很多其他的線索幫助我們理解某人在說什么。人類使用但是語音識別器不使用的語境包括:
談話的歷史過程和正在討論的話題。
人在說話時的視覺線索,例如面部表情和唇部運動。
對談話對象的了解。
現在,Android 的語音識別器掌握你的通訊錄,所以它能夠準確地識別你朋友的名字。地圖類產品中的語音搜索會使用你的地理定位來縮小你想要導航的位置的范圍。
自動語音識別(ASR)系統的準確度確實在這類信號的幫助下得到了提升。但是,這里我們僅對可以使用的語境類型和如何使用又有一個初步了解。
部署與應用
對話語音識別的最新進展都是不可部署的。在思考什么讓一個新的語音識別算法變得可部署的時候,衡量其延遲和所需算力是有幫助的。這二者是有關聯的,一般情況下,如果一個算法所需要的計算力增加,那么它帶來的延遲也會隨之增加。但是為了簡單起見,我將分開討論它們。
延遲:我所指的「延遲」指從用戶說話結束到轉錄完成所經歷的時間。低延遲是 ASR 中的一個常見產品約束。它能夠顯著地影響用戶體驗。ASR 系統中數十毫秒的延遲需求是很常見的。雖然這聽起來很極端,但是請別忘記,產生轉錄結果通常是一系列昂貴計算中的第一步。例如在語音搜索中,實際的網絡規模搜索必須在語音識別之后才能進行。
雙向循環層是消除延遲的改進中的很好的例子。所有最新的對話語音識別的先進結果都使用了它們。問題在于:在用戶結束語音之前,我們不能用第一個雙向層計算任何東西。所以延遲會隨著話語長度的增加而增加。
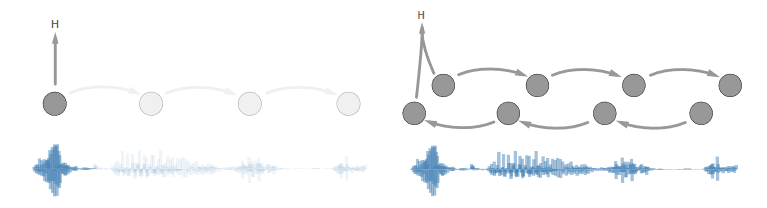
左圖:出現前向循環的時候我們可以立即開始轉錄。
右圖:出現雙向循環的時候,我們必須等待所有語音都到達之后才能開始轉錄。
在語音識別中結合未來信息的有效方式仍待研究和發現。
計算:轉錄一個話語所需的計算力是一種經濟約束。我們必須考慮語音識別器準確率提升的性價比。如果一項改進未能滿足經濟閾值,那么它是無法部署的。
下一個五年
語音識別領域仍然存在不少開放性挑戰問題,包括:
將語音識別能力擴展至新的領域、口音,以及遠場、低信噪比的語音中。
在語音識別過程中結合更多的語境信息。
音源和聲源分離。
語義錯誤率和新型的語音識別器評價方法
超低延遲和超高效的推理
轉自:鳳凰網科技

